P · 01
On-device by default.
Audio leaves your file only if you point UtterPad at a cloud model. The default engines run entirely on your Mac. No network, no telemetry.
A native macOS workshop for turning audio and video into SRT, VTT, TXT, ASS and JSON subtitles — fast, batch-friendly, with the engine you pick. No SaaS round-trips. No usage caps.
Audio leaves your file only if you point UtterPad at a cloud model. The default engines run entirely on your Mac. No network, no telemetry.
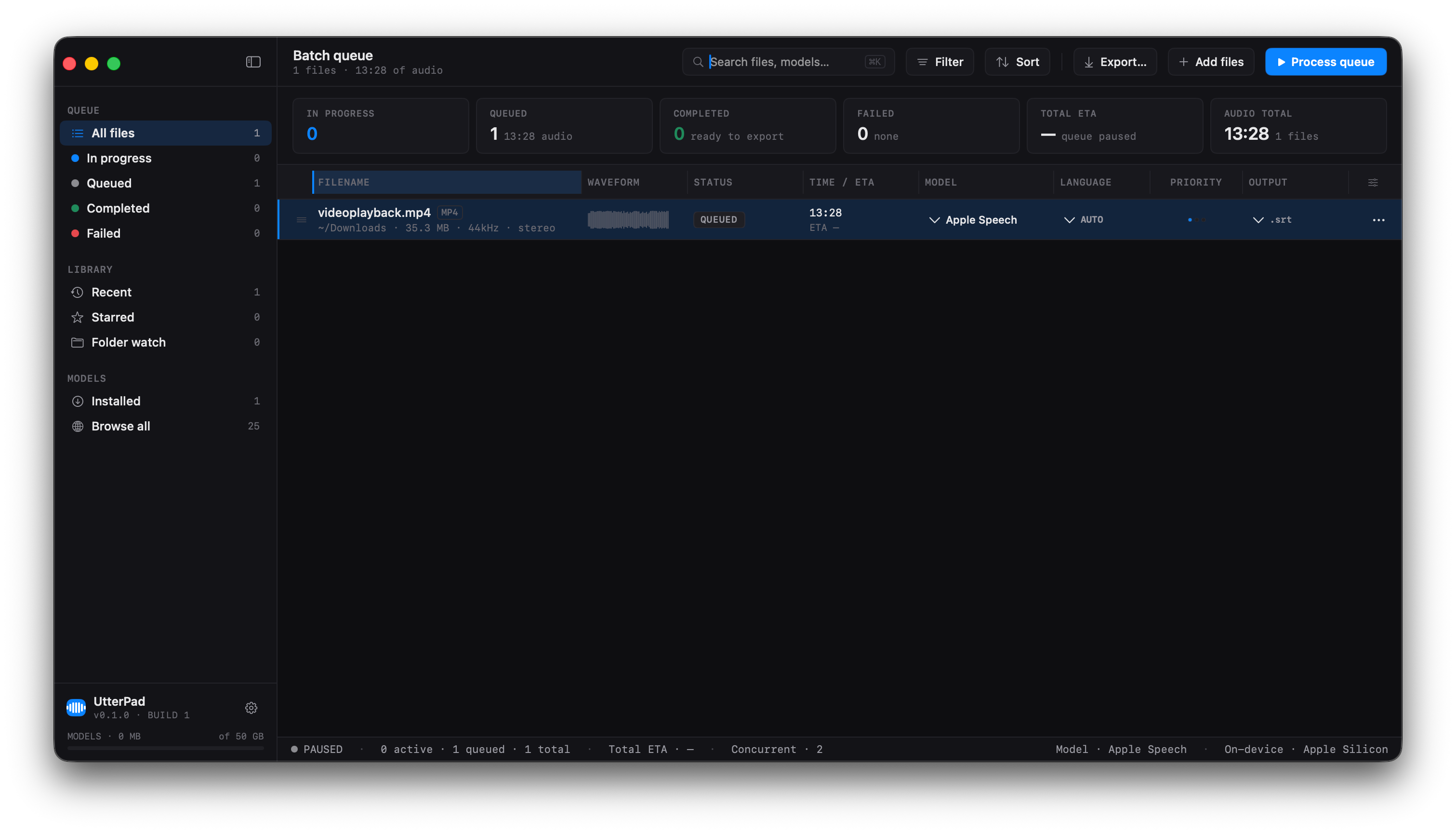
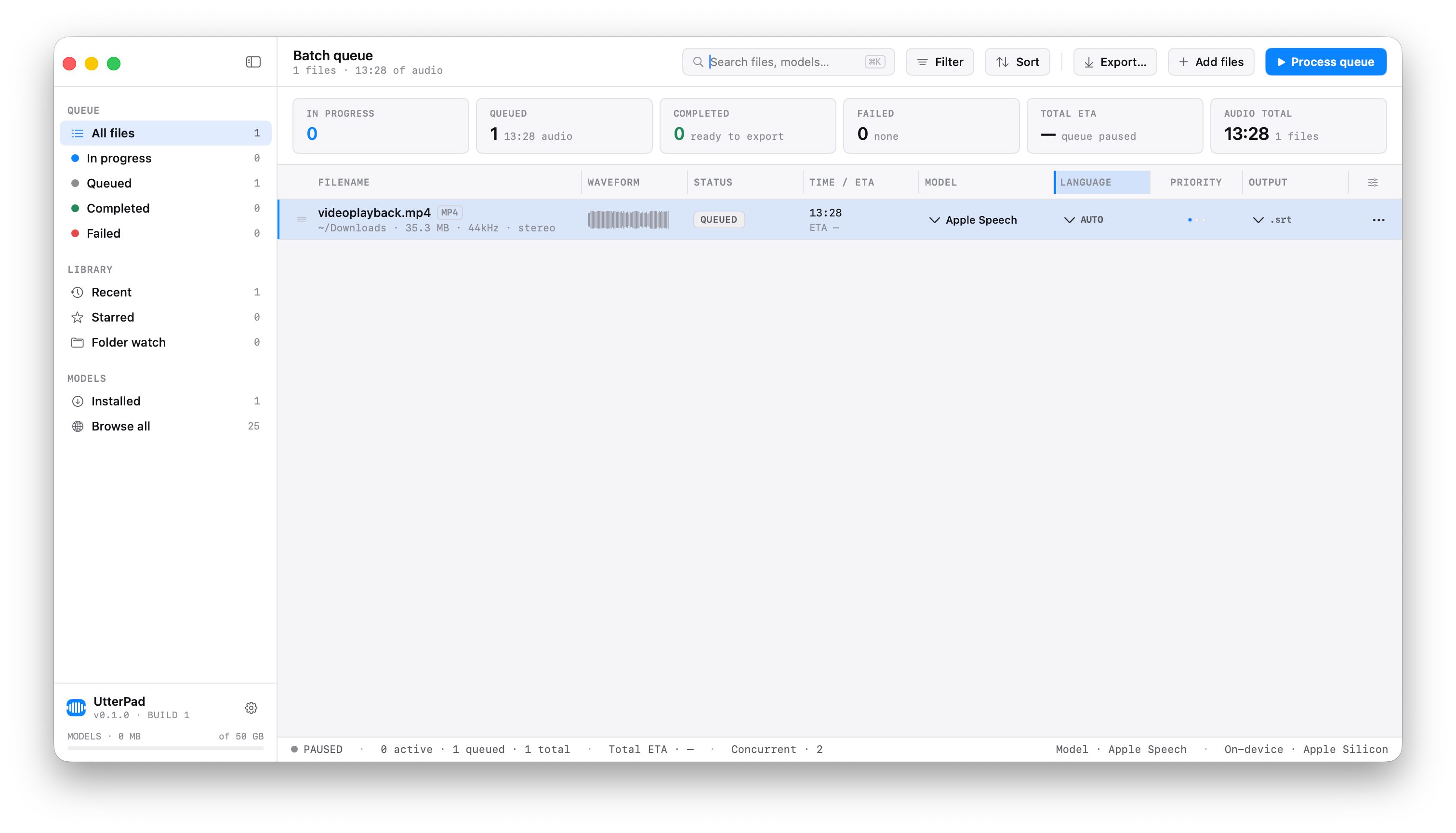
Batch queue with per-row model, language, output-format and folder overrides. Drag-reorderable, drag-resizable columns. Phased progress bars that reset between extract and transcribe.
Each completed job auto-exports .srt, .vtt,
.txt, .ass and .json — beside the source
or to a folder you pick per file.
generateContent.Free for 30 days. $19 lifetime if you stick around.